Cuando una empresa instala la capacidad de consultar sus datos en lenguaje natural, el objetivo declarado es democratizar el acceso a la información: que cualquier persona del equipo pueda preguntar "¿cuánto hemos vendido esta semana en la zona norte?" sin necesitar a un analista que le prepare el informe.
Lo que pocas implementaciones consideran con suficiente rigor antes de ir a producción es que democratizar el acceso a las preguntas no es lo mismo que democratizar el acceso a los datos.
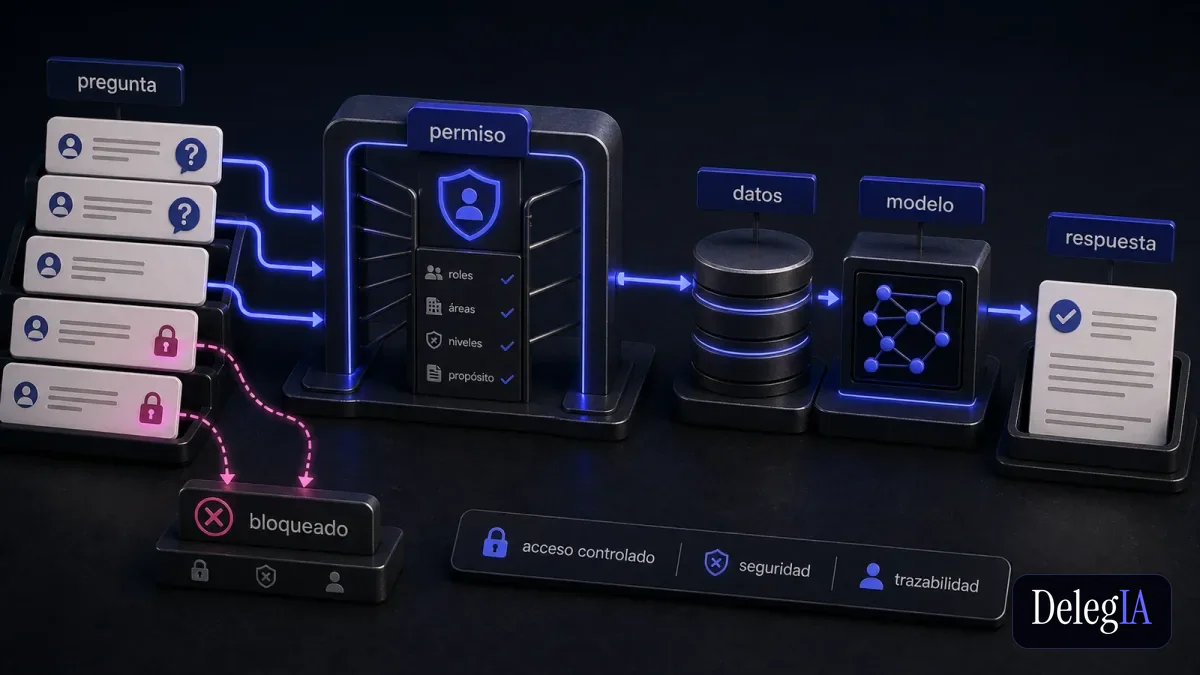
Si el sistema que traduce lenguaje natural a SQL no tiene controles de permisos bien definidos, la consulta "¿cuánto hemos vendido esta semana?" puede devolver datos de canales, márgenes o clientes que el usuario no debería ver según la política de acceso de la empresa.
Este artículo describe qué significa implementar bien los controles de permisos en un sistema de consulta de datos en lenguaje natural con IA, por qué es más complejo de lo que parece y qué elementos concretos hay que definir antes de ponerlo en producción.
Índice del artículo
El problema de permisos que las demos no muestran#
La demo habitual de un sistema de consulta en lenguaje natural con IA es impresionante: el usuario escribe una pregunta, el sistema la interpreta, genera el SQL correspondiente y devuelve una tabla o un gráfico en segundos. La demo muestra velocidad y accesibilidad.
Lo que la demo no muestra es qué pasa cuando el usuario pregunta algo que no debería poder preguntar.
En un sistema sin controles de permisos, la capa de IA tiene acceso a toda la base de datos sobre la que opera.
**Si un responsable de zona comercial pregunta "¿cuál es el margen de nuestros contratos con la cadena X?", el sistema puede responder con datos financieros que en el esquema de permisos del ERP ese responsable no tenía
acceso a ver.** El acceso a la pregunta en lenguaje natural ha saltado por encima del control de acceso que existía en el sistema original.
Esto no es un fallo de la IA en el sentido técnico del término. Es una consecuencia de no haber diseñado la capa de permisos del sistema de consulta de forma coherente con la política de acceso de la empresa.
La IA hace lo que puede hacer: responder preguntas sobre los datos a los que tiene acceso. El problema es que tiene acceso a más datos de los que debería tener el usuario que está preguntando.
Tres mecanismos para implementar permisos que funcionan#
Primer mecanismo: acceso a vistas, no a tablas completas.
El sistema de IA no debe conectarse directamente a las tablas de producción de la base de datos. Debe conectarse a vistas o datasets específicos que ya tienen los datos filtrados por los criterios de acceso que corresponden a cada rol.
Si un director comercial solo puede ver datos de sus clientes y no de los clientes de otros directores, la vista que el sistema de IA usa para ese director solo contiene los registros de esos clientes. La IA no puede acceder a lo que no está en la vista, aunque el usuario formule una pregunta que en lenguaje natural parezca razonable hacerla.
Este mecanismo es el más efectivo y el más sencillo de mantener porque los controles de acceso se definen en la capa de datos, no en la capa de IA. Si el director cambia de territorio, se actualiza su vista. No hay que reconfigurar el sistema de IA.
Segundo mecanismo: validación de la consulta SQL generada antes de ejecutarla.
Entre el paso de interpretar la pregunta en lenguaje natural y el paso de ejecutar el SQL generado, el sistema puede incluir una capa de validación que comprueba que el SQL generado no accede a tablas o campos para los que el usuario no tiene permiso.
Este mecanismo es más flexible que el primero porque permite que un mismo usuario acceda a distintos datasets según el contexto de la pregunta, pero requiere mantener una matriz de permisos que se compare con cada consulta generada.
En implementaciones complejas, esta capa de validación puede ser costosa de mantener cuando la estructura de datos cambia.
Tercer mecanismo: auditoría y trazabilidad de cada consulta.
Independientemente del mecanismo de control de acceso que se implemente, toda consulta ejecutada debe quedar registrada con el identificador del usuario, la pregunta en lenguaje natural, el SQL generado y la fecha y hora de ejecución. Este registro no evita accesos no autorizados, pero permite detectarlos y responder ante ellos.
La auditoría también tiene valor operativo: permite identificar qué tipos de preguntas hace cada rol del equipo, qué consultas producen errores frecuentemente y qué datos se están usando más de lo esperado. Esa información es útil para mejorar el sistema y para ajustar los permisos cuando se detectan patrones de uso que no estaban previstos.
No todos los datos de una empresa tienen el mismo nivel de sensibilidad. Los datos de actividad comercial (ventas por producto, tiempos de entrega, stock disponible) tienen un régimen de acceso diferente al de los datos de márgenes por cliente, al de los datos salariales del equipo o al de los datos financieros consolidados.
Un error frecuente en implementaciones de consulta en lenguaje natural es usar una sola conexión con acceso a todo para simplificar la configuración técnica. El resultado es que el nivel de permisos más permisivo se convierte en el nivel de permisos de todos los usuarios del sistema.
La solución correcta es definir varios perfiles de acceso antes de la implementación: qué datos puede ver cada rol, qué tipos de análisis puede ejecutar sobre esos datos y qué resultados pueden ser exportados fuera del sistema.
Esa matriz de permisos se implementa en la capa de datos (mediante vistas o esquemas separados) y el sistema de IA se configura para cada perfil de forma independiente.
Para datos sujetos a regulación (datos de carácter personal bajo RGPD, datos financieros sujetos a auditoría, datos de salud), la implementación requiere además documentar el flujo de tratamiento de datos que pasa por el sistema de IA y verificar que es compatible con los requisitos regulatorios aplicables.
Lo que hay que tener definido antes de poner en producción#
Antes de activar un sistema de consulta de datos en lenguaje natural con IA para uso del equipo, hay cinco elementos que deben estar definidos y documentados.
La matriz de acceso por rol. Qué datos puede ver cada perfil de usuario: qué tablas, qué campos, qué filtros de registro se aplican por defecto. Esta matriz debe ser el punto de partida de la implementación técnica, no algo que se define a posteriori cuando ya hay usuarios en el sistema.
El catálogo de métricas definidas. Cuando un usuario pregunta "¿cuál es nuestro margen?" el sistema necesita saber qué definición de margen usar.
Si no hay un catálogo de métricas documentado que el sistema de IA carga como contexto, el sistema elegirá una interpretación por defecto que puede no coincidir con la definición que usa el equipo financiero.
El mecanismo de control de permisos. Vistas separadas por rol, validación de SQL antes de ejecución, o una combinación de ambos. La elección depende de la complejidad del esquema de datos y de los recursos técnicos disponibles para mantener el sistema.
El sistema de auditoría de consultas. Qué queda registrado en cada consulta, dónde se almacena ese registro, quién tiene acceso a él y durante cuánto tiempo se conserva.
El proceso de respuesta ante accesos no autorizados. Qué pasa cuando la auditoría detecta una consulta que accedió a datos que el usuario no debería haber visto: quién recibe la alerta, quién investiga y quién decide qué acción tomar.
Para ver cómo se instala esta infraestructura de acceso a datos con inteligencia artificial de forma que sea segura y gobernable, la página de análisis de datos con IA describe el enfoque completo de DelegIA.
Preguntas frecuentes
¿Es seguro conectar la IA directamente a la base de datos de producción?+
Generalmente no es recomendable. La base de datos de producción contiene todos los datos de la empresa sin filtros de acceso por rol.
La práctica recomendada es crear una capa de datos separada (un data warehouse o un conjunto de vistas específicas) que tenga los datos necesarios para el análisis y los controles de acceso correctamente configurados. La IA se conecta a esa capa, no directamente a producción.
¿El RGPD afecta a los sistemas de consulta de datos en lenguaje natural?+
Sí, especialmente cuando los datos que el sistema puede consultar incluyen datos de carácter personal: datos de clientes, datos de empleados o cualquier información que identifique a personas físicas.
En esos casos, el sistema de IA forma parte del flujo de tratamiento de datos y debe estar documentado como tal en el registro de actividades de tratamiento de la empresa.
Además, los datos de carácter personal no deben estar accesibles a usuarios sin necesidad legítima de tratarlos, lo que refuerza la necesidad de la matriz de acceso por rol.
¿Cómo sé si mi implementación actual tiene permisos bien configurados?+
Hay una prueba sencilla: elige un usuario con perfil de acceso restringido y hazle formular consultas sobre datos que ese perfil no debería ver. Si el sistema devuelve esos datos, los permisos no están correctamente configurados.
Si el sistema devuelve un error o un resultado vacío, los controles están funcionando. Esta prueba debe hacerse antes de dar acceso al sistema a usuarios de producción, no después.
Consultar datos en lenguaje natural con IA democratiza las preguntas, pero puede romper permisos. Qué definir antes de ponerlo en producción.
Si sQL lenguaje natural IA ya aparece dentro de tu empresa, conviene revisar qué parte del flujo debe ejecutar la IA, qué datos necesita y quién valida el resultado antes de escalarlo.
El objetivo no es añadir otra herramienta, sino instalar una infraestructura que reduzca fricción, mantenga control humano y permita medir si el sistema mejora la operación.
El siguiente paso es aterrizar sQL lenguaje natural IA en un caso concreto: qué proceso se quiere mejorar, qué datos lo sostienen y qué parte debe seguir bajo criterio humano.
Si necesitas ayuda para implementar IA en tu empresa con criterio, puedes solicitar un presupuesto y contarnos qué área quieres mejorar. Revisamos el caso y te respondemos en menos de 24 horas.
Implementa IA en tu empresa sin improvisar
Analizamos tu caso y te proponemos una infraestructura de IA adaptada al problema real, no un paquete genérico de herramientas.