29 de mayo de 2026Actualizado 5 de junio de 20268 min2379 palabras
Usar IA para analizar datos parece sencillo hasta que la empresa toma una decisión equivocada con una confianza que no tenía justificación. El sistema respondió. El número salió. Y nadie preguntó si la pregunta era la correcta.
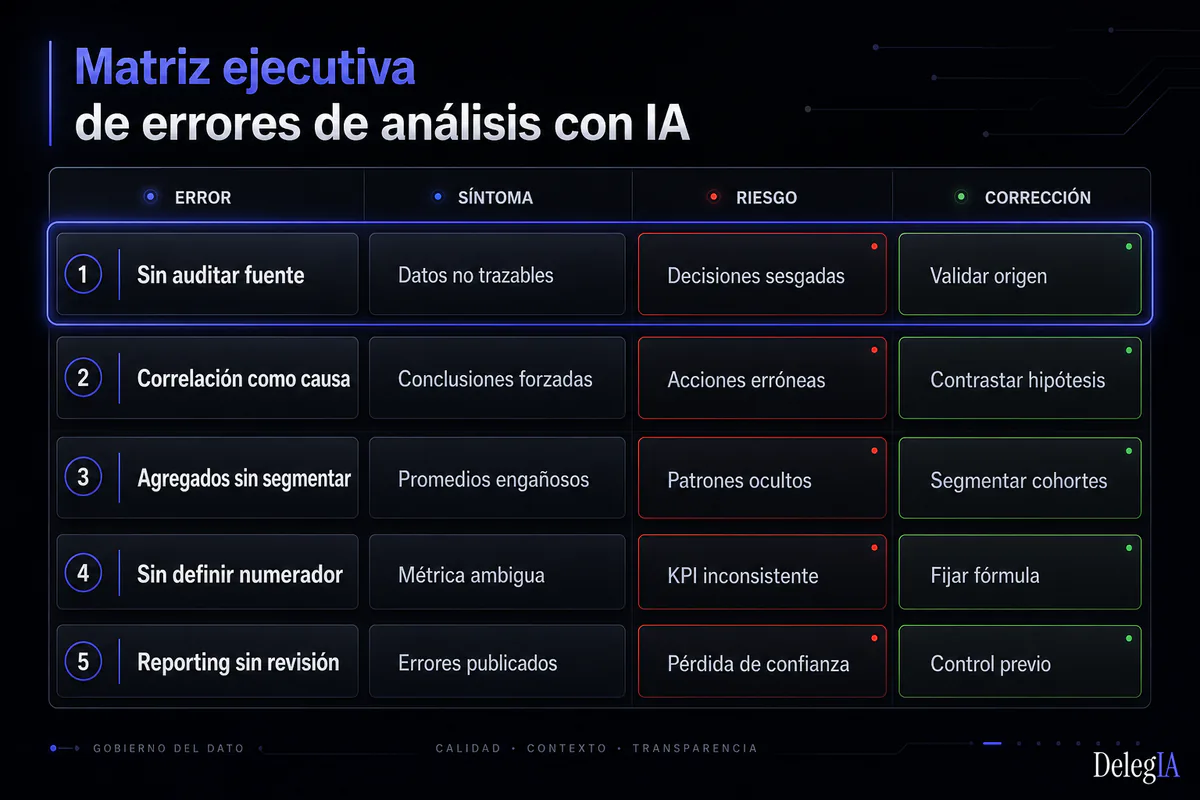
Este artículo describe cinco antipatrones documentados en entornos de analítica con IA: directores financieros, de operaciones o BI que trabajan con dashboards conectados a modelos de lenguaje o herramientas de análisis automático y arrastran el riesgo de validar la salida sin verificar la entrada.
Cada error tiene su síntoma, su causa, un ejemplo de producción y una corrección concreta. Al final, una pregunta de control universal que conviene hacerse antes de cualquier decisión apoyada en análisis de IA.
Índice del artículo
Error 1: preguntar a la IA sobre datos sin auditar la fuente#
Síntoma. El director de operaciones le pregunta al asistente de analítica: "¿Cuáles son nuestros productos con mayor margen este trimestre?" y obtiene una lista ordenada. La toma como respuesta y decide dónde concentrar la fuerza de ventas.
Por qué pasa. La IA no sabe si los datos que tiene son correctos. Responde con lo que hay. Si el ETL que alimenta el warehouse tiene un error de mapeo desde el ERP, o si ciertos canales de venta aún no han cerrado la conciliación del trimestre, el modelo trabaja sobre una base defectuosa y lo hace con total fluidez.
La IA no tiene acceso a la intención detrás del dato, solo al dato mismo.
Ejemplo verificable. Una distribuidora con varios almacenes consolida ventas en un cuadro de mando centralizado. Uno de los almacenes registra devoluciones como ventas negativas en una columna diferente a la usada por los demás. El modelo de analítica no detecta el criterio distinto.
El producto A aparece con margen del 28% cuando en la operativa del almacén 3 el margen documentado es negativo.
Cómo se corrige. Antes de lanzar la consulta a la IA, establecer un protocolo de calidad de datos: fecha de última actualización, tasa de registros nulos o inconsistentes en los campos clave, y confirmación de que el periódo analizado está cerrado.
No es un proceso manual: puede automatizarse como un gate previo que el sistema ejecuta antes de permitir la consulta. Si la calidad no supera el umbral definido, el sistema bloquea y avisa.
Pregunta de control. ¿Los datos que el sistema ha consultado están auditados, cerrados y sin registros pendientes de conciliar?
Error 2: confundir correlación con causa cuando la IA enuncia patrones#
Síntoma. El sistema detecta que "los clientes que contratan el servicio B tienen un 40% menos de cancelaciones en el primer año". El director comercial decide incluir el servicio B en todos los contratos nuevos para reducir churn. La tasa de cancelación no mejora.
Por qué pasa. Los modelos de analítica son muy buenos detectando correlaciones en datos históricos. No tienen capacidad causal salvo que se entrenen específicamente para eso, y la mayoría de las herramientas de BI con IA no lo hacen. La IA enuncia patrones como si fueran mecanismos, y el receptor los interpreta como explicaciones.
Ejemplo verificable. En una empresa de servicios, los clientes que contratan el servicio B son precisamente los que ya tienen mayor madurez operativa y más integrados los procesos internos. Eso los hace menos propensos a cancelar, pero no por el servicio B: el servicio B es solo el indicador de un perfil.
Obligar a clientes de menor madurez a contratar el servicio B no les da esa madurez.
Cómo se corrige. Cuando la IA detecte un patrón de correlación, el analista debe abrir una segunda pregunta: ¿qué otras variables comparten los elementos de este grupo? ¿Existe un mecanismo plausible entre A y B o simplemente coocurren? Para decisiones de alta implicación, la correlación es una hipótesis de trabajo, no una conclusión.
La validación requiere un experimento controlado o un análisis causal explícito.
Pregunta de control. ¿Hay un mecanismo concreto que explique por qué A causa B, o solo sabemos que aparecen juntos en los datos históricos?
Error 3: confiar en agregados sin segmentar (el riesgo de Simpson en empresa mediana)#
Síntoma. El informe mensual muestra que el tiempo medio de resolución de incidencias ha bajado de 4,2 a 3,1 días. Interpretación: la operativa mejora. Pero las reclamaciones de clientes aumentan.
Por qué pasa. La paradoja de Simpson ocurre cuando una tendencia positiva en el agregado esconde tendencias negativas en los subgrupos. Es un fenómeno matemático bien documentado, pero los dashboards automáticos y los resúmenes de IA presentan métricas agregadas por defecto. Si nadie pide la desagregación, nadie la ve.
Ejemplo verificable. En una empresa con dos líneas de servicio, la línea A (incidencias técnicas, alto volumen, baja complejidad) cierra tickets en 1,5 días y ha ganado peso en el mix. La línea B (proyectos, alta complejidad, bajo volumen) ha pasado de 7 a 9 días de resolución.
El agregado mejora porque el mix ha cambiado, no porque los procesos sean más rápidos. La línea B, que es la que afecta a los clientes de mayor valor, está empeorando.
Cómo se corrige. Toda métrica agregada debe tener configurada una desagregación obligatoria por al menos una dimensión relevante antes de llegar al cuadro de mando directivo. En analítica con IA, esto se resuelve con un prompt de verificación sistemática: "Desglosa esta métrica por [segmento de negocio / canal / tipología de cliente]".
No como consulta opcional, sino como parte del flujo estándar antes de comunicar el dato.
Para ver más sobre cómo estructurar el reporting con IA sin que estos sesgos se cuelen en los informes automáticos, consulta la guía de reporting de empresa con IA.
Pregunta de control. ¿El dato agregado refleja lo que ocurre en cada segmento, o el mix de actividad ha cambiado y está distorsionando la tendencia?
Error 4: preguntar en lenguaje natural sin definir el numerador y el denominador#
Síntoma. El CFO pregunta al asistente de analítica: "¿Cuál es nuestro margen este trimestre?" y obtiene un número. Ese número no coincide con el que calcula el equipo financiero en la hoja de cierre. Nadie sabe cuál es correcto.
Por qué pasa. "Margen" puede significar cosas distintas según quien lo use: margen bruto sobre ventas netas, margen bruto sobre ventas brutas, margen de contribución, margen EBITDA, margen neto. Cuando la consulta llega en lenguaje natural, el modelo elige una interpretación.
Si no está explicitada en el esquema de datos ni en el prompt del sistema, el modelo elige la más frecuente en sus datos de entrenamiento, que puede no coincidir con la definición contable de la empresa.
Ejemplo verificable. Una empresa de servicios profesionales calcula el margen de proyecto como horas vendidas menos horas incurridas sobre horas vendidas. El modelo de analítica, sin esa definición explícita, calcula ingresos menos coste de personal sobre ingresos. Ambas son métricas válidas.
Son distintas y llevan a conclusiones distintas sobre qué proyectos son rentables.
Cómo se corrige. Toda consulta analítica sobre indicadores clave debe incluir la definición explícita del numerador y el denominador antes de ejecutarse. Esto se formaliza en un glosario de métricas del negocio que el sistema de analítica con IA carga como contexto obligatorio.
Si la consulta usa un término que no está en el glosario, el sistema debe devolver una aclaración antes de responder: "¿Qué definición de margen quieres usar?" No es una limitación técnica, es un diseño deliberado.
Si quieres entender cómo se instala esta capa de definición dentro de un departamento de analítica estructurado, la página de análisis de datos con IA describe el enfoque de DelegIA.
Pregunta de control. ¿El sistema usa la misma definición de este indicador que el equipo financiero o de operaciones que va a recibir el dato?
Error 5: automatizar el reporting sin gate de revisión humana#
Síntoma. El informe semanal de ventas se genera automáticamente cada lunes y se distribuye al equipo directivo. Nadie lo revisa antes de enviarlo. En la semana 8, el informe incluye datos del trimestre anterior por un fallo en la parametrización de fechas. La reunión de dirección del lunes toma decisiones sobre datos de hace tres meses.
Por qué pasa. La automatización del reporting es uno de los primeros casos de uso donde se despliega IA en empresas medianas, porque el ahorro de tiempo es evidente. El problema es que la automatización elimina el momento en que un humano pasaba por los datos antes de presentarlos.
Ese momento, que muchas veces parecía rutinario, era en realidad un gate de detección de anomalías.
Ejemplo verificable. Una empresa de distribución con 30 personas automatiza el informe de rentabilidad por cliente. En una semana, uno de los proveedores de datos actualiza su API y cambia el formato de las fechas.
El sistema no detecta el error de parseo, sigue generando el informe con los últimos valores válidos (de tres semanas antes) y los directores toman decisiones de descuento basadas en cifras desactualizadas antes de que nadie detecte el problema.
Cómo se corrige. Todo pipeline de reporting automatizado necesita un gate de calidad antes del envío: verificación de que los datos corresponden al período correcto, que no hay valores nulos en métricas críticas, y que las variaciones respecto a la semana anterior no superan umbrales de anomalía definidos.
Si el gate falla, el informe se bloquea y se notifica al responsable antes de distribuir. La revisión humana no tiene que ser exhaustiva: basta con validar las señales de alerta que el sistema ya ha filtrado.
Para ver cómo este tipo de infraestructura se aplica a la operativa más amplia de la empresa, consulta el artículo sobre departamento de operaciones con IA.
Pregunta de control. ¿Existe un gate automático que verifica la integridad de los datos antes de que el informe llegue a quienes toman decisiones?
Antes de revisar los errores de manera aislada, conviene tener el marco completo en una sola vista. Esta es la estructura que cualquier director de datos, CFO o responsable de BI puede usar como checklist de auditoría interna antes de distribuir un análisis basado en IA.
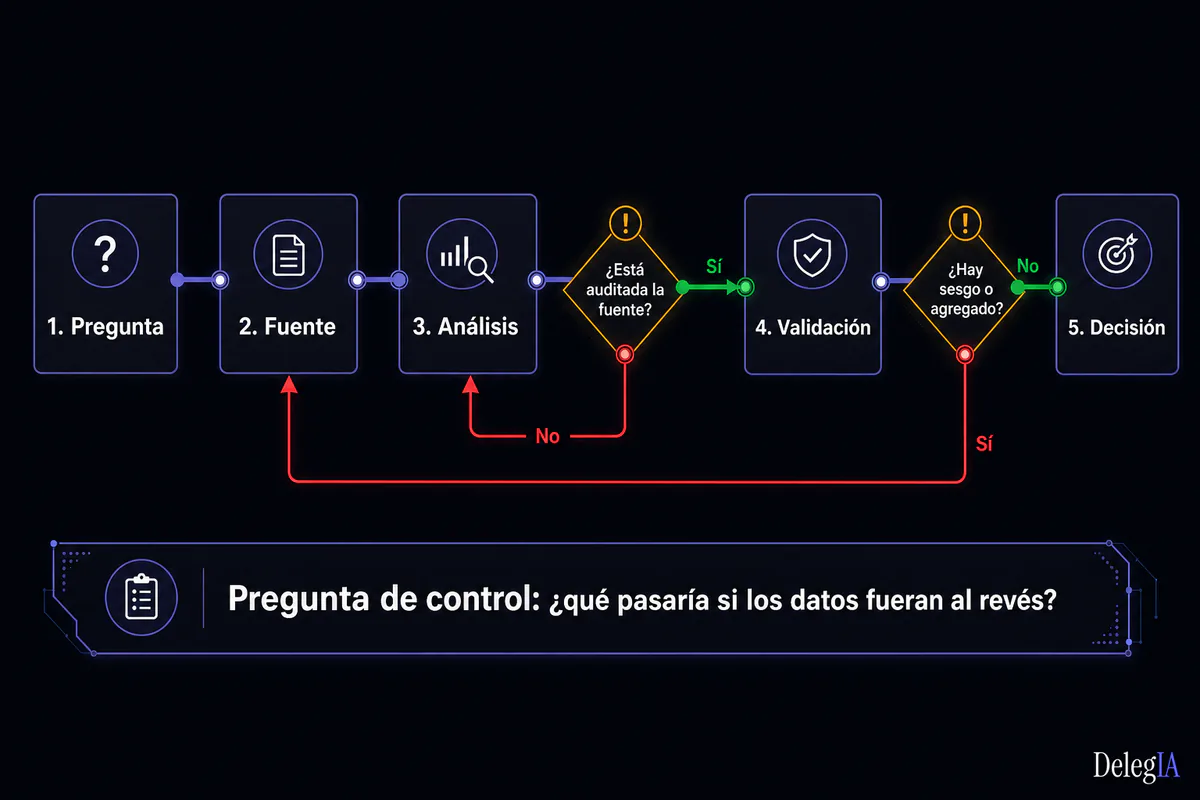
El flujo de validación antes de cualquier decisión con IA#
Los cinco errores anteriores tienen algo en común: todos ocurren porque la IA responde y el humano acepta. El antídoto no es desconfiar de la IA, sino diseñar un flujo que incluya un paso de verificación antes de pasar de la respuesta a la decisión.
El flujo tiene cuatro momentos:
1. Entrada de datos. Los datos que alimentan la consulta deben estar auditados, con fecha de cierre documentada y con una tasa de calidad conocida. Si no se puede garantizar esto, la consulta no debería ejecutarse.
2. Pregunta a la IA. La consulta debe incluir la definición exacta de los indicadores, el período concreto y la segmentación esperada. Las preguntas ambiguas en lenguaje natural producen respuestas que parecen precisas pero no lo son.
3. Respuesta de la IA. El sistema devuelve un análisis. Aquí conviene aplicar dos comprobaciones básicas: ¿el resultado es coherente con lo que el equipo espera ver? ¿Los órdenes de magnitud tienen sentido? Una anomalía evidente es una señal de que algo en la entrada o en el modelo no funciona bien.
4. Gate de verificación humana. Antes de que el análisis llegue a una decisión o se distribuya en un informe, un responsable con criterio sobre el negocio valida que el resultado tiene sentido en contexto. No es una revisión exhaustiva. Es una comprobación de sentido común con datos conocidos.
Solo después de pasar el gate, el análisis entra en el proceso de decisión.
Este no es un flujo teórico. Es el diseño que DelegIA instala en los departamentos de analítica de las empresas donde trabaja: una infraestructura que automatiza donde tiene sentido y mantiene la supervisión humana donde el coste de error es alto.
Antes de tomar cualquier decisión apoyada en un análisis de IA, hay una pregunta que conviene hacerse siempre:
¿Sé con certeza qué datos usó el sistema, qué definiciones aplicó y quién ha verificado que el resultado es coherente con la realidad del negocio antes de llegar aquí?
Si la respuesta a cualquiera de las tres partes es "no sé" o "no nadie", el análisis no está listo para convertirse en decisión.
La IA puede procesar más rápido, detectar más patrones y generar informes con menos esfuerzo. Pero no tiene contexto sobre qué está en juego, no sabe si los datos de entrada son fiables y no puede detectar si la pregunta que se le hace es la pregunta correcta. Eso sigue siendo responsabilidad del equipo directivo.
Preguntas frecuentes
¿Significa esto que no se puede confiar en la IA para analizar datos?+
No. Significa que la confianza debe ser proporcional al rigor del proceso que rodea al sistema. La IA es muy fiable cuando los datos de entrada están bien definidos, la consulta es precisa y existe un gate de verificación antes de actuar. El error no está en la herramienta, está en usarla sin ese proceso.
¿Cómo se implementa un gate de verificación sin ralentizar el reporting automático?+
El gate no tiene por qué ser manual en todos los casos. Para reportes recurrentes, puede automatizarse como un conjunto de comprobaciones previas: fechas correctas, ausencia de nulos en métricas críticas, variaciones dentro de rangos esperados. Si todas pasan, el informe sale. Si alguna falla, se bloquea y notifica.
El tiempo añadido es mínimo; el riesgo que elimina es alto.
¿Qué pasa si la empresa no tiene un glosario de métricas formalizado?+
Es el primer paso antes de conectar cualquier herramienta de analítica con IA. Sin ese glosario, el sistema de IA elige interpretaciones por defecto que pueden no coincidir con las del equipo.
El glosario no tiene que ser exhaustivo desde el principio: basta con documentar las diez métricas que más se usan en decisiones de dirección y asegurarse de que el sistema de analítica las carga como contexto antes de responder.
Conclusiones
Cinco antipatrones documentados al usar IA para analizar datos en empresas medianas: síntoma, causa, corrección y pregunta de control antes de decidir.
Si errores análisis datos con IA ya aparece dentro de tu empresa, conviene revisar qué parte del flujo debe ejecutar la IA, qué datos necesita y quién valida el resultado antes de escalarlo.
El objetivo no es añadir otra herramienta, sino instalar una infraestructura que reduzca fricción, mantenga control humano y permita medir si el sistema mejora la operación.
El siguiente paso es aterrizar errores análisis datos con IA en un caso concreto: qué proceso se quiere mejorar, qué datos lo sostienen y qué parte debe seguir bajo criterio humano.
Si necesitas ayuda para implementar IA en tu empresa con criterio, puedes solicitar un presupuesto y contarnos qué área quieres mejorar. Revisamos el caso y te respondemos en menos de 24 horas.
Implementa IA en tu empresa sin improvisar
Analizamos tu caso y te proponemos una infraestructura de IA adaptada al problema real, no un paquete genérico de herramientas.