25 de mayo de 2026Actualizado 5 de junio de 20268 min1984 palabras
Tener una voz de marca definida en un documento de estilo no es suficiente para producir contenido con IA que suene a la empresa. La mayoría de los equipos lo descubre tarde: el modelo genera textos gramaticalmente correctos, pero genéricos. Intercambiables. Sin personalidad.
El problema no está en el modelo. Está en que la voz no se ha operacionalizado. Existe como concepto, no como sistema de revisión verificable.
Este artículo describe cómo construir ese sistema: el documento de voz operacionalizable, los tres ejes de revisión humana y el flujo de entrenamiento iterativo que permite pasar de outputs genéricos a contenido que suena, efectivamente, a la empresa.
Índice del artículo
Por qué la mayoría de documentos de voz no funcionan con IA#
Un brief de marca estándar dice cosas como "cercano pero profesional", "innovador sin tecnicismos" o "directo y confiable". Son descriptores válidos para un copywriter humano que tiene contexto previo. Para un sistema de IA, son instrucciones vacías.
La IA no tiene intuición. No sabe lo que significa "cercano pero profesional" sin ejemplos, sin contrastes y sin criterios de evaluación objetivos. Un documento de voz que no incluye esos tres elementos no es un documento de voz operacionalizable: es un aspiracional.
La diferencia entre un documento que funciona y uno que no es que el primero permite responder a la pregunta: ¿este output pasa o no pasa? Con criterios medibles, sin necesidad de que lo evalúe el director creativo.
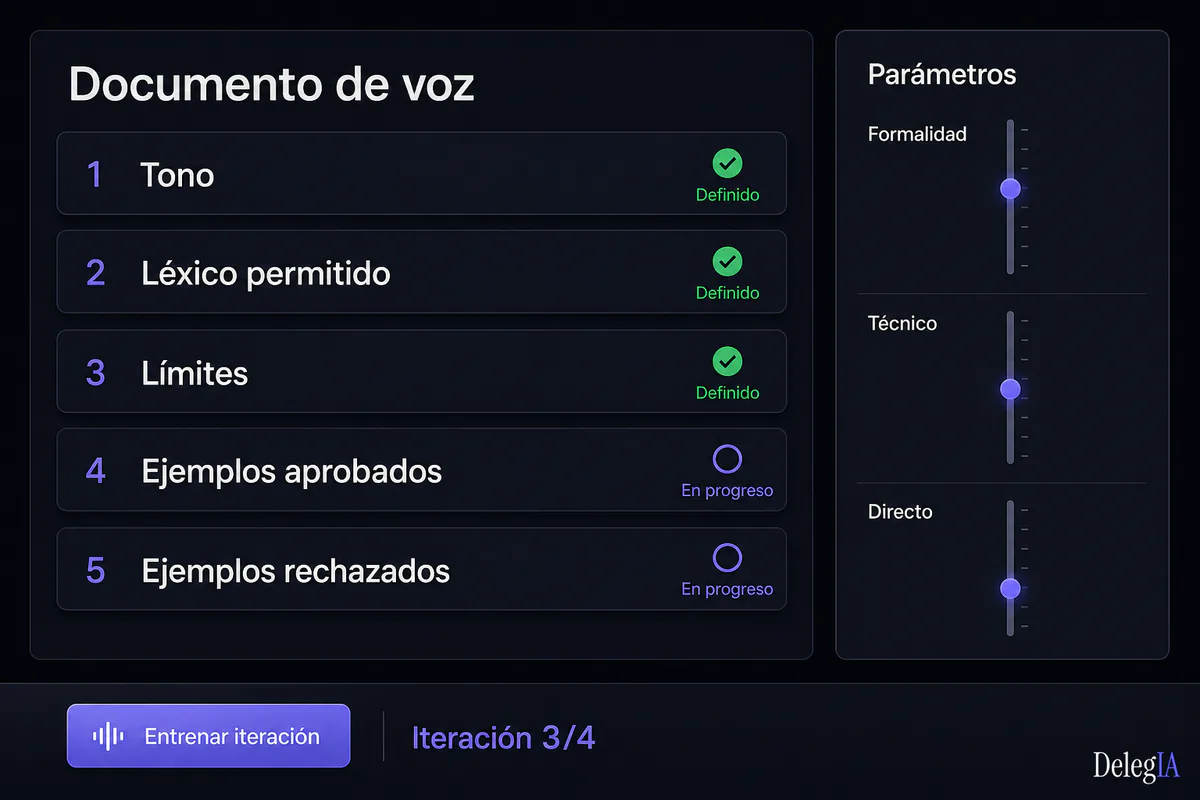
El documento de voz operacionalizable: cinco bloques#
El documento de voz operacionalizable no es un PDF de brand guidelines. Es un archivo de configuración del sistema. Tiene cinco bloques concretos:
Bloque 1: Perfil tonal con contrastes
No "directo y técnico". Sino: "directo como un diagnóstico clínico, técnico cuando el contexto lo requiere, sin hype, sin motivacional". Cada atributo va acompañado de su opuesto explícito: qué NO es la voz.
El contraste es el que le da utilidad al modelo. Sin el polo negativo, el modelo no sabe dónde está el límite.
Bloque 2: Léxico propio y léxico prohibido
Una lista de palabras y construcciones que la empresa usa de forma recurrente: sus verbos centrales, sus sustantivos canónicos, sus frases de marca. Y una lista negra de términos que, aunque correctos en castellano, no encajan con la voz: palabras prohibidas, giros que suenan a otro sector, tecnicismos evitados.
Ambas listas deben ser cortas. Diez a quince entradas en cada columna. Demasiadas entradas generan instrucciones contradictorias.
Bloque 3: Patrones de ritmo y longitud
La voz no es solo qué se dice. Es cómo se dice. El ritmo determina si un párrafo suena a la empresa o no, aunque el léxico sea correcto.
Este bloque define: longitud máxima de párrafo en caracteres, número de frases por párrafo, longitud de la frase de cierre de cada bloque, presencia o ausencia de preguntas retóricas, uso de listas y en qué condiciones.
Bloque 4: Patrones de apertura y cierre
Las primeras tres frases de un texto y las últimas dos son las que más revelan si el modelo está capturando la voz o no. Incluir ejemplos verificados de aperturas que suenan bien y aperturas que no. Lo mismo con los cierres.
Tres a cinco ejemplos de cada tipo. No más. El modelo necesita patrón, no biblioteca.
Bloque 5: Tabla de verificación
Una tabla de cinco a ocho filas con criterios binarios. Cada fila es un criterio (sí/no): ¿hay em dashes?, ¿hay pregunta retórica en la apertura?, ¿el párrafo más largo supera 300 caracteres?, ¿aparece léxico de la lista negra?
Esta tabla es lo que convierte el documento de voz en un instrumento de revisión automatizable. Sin ella, la revisión depende del criterio subjetivo del revisor.
Cuando el sistema produce un output, la revisión humana no puede ser una lectura general de "si suena bien". Eso es lento, inconsistente e incalculable. La revisión humana tiene que ser estructurada en tres ejes concretos.
Eje 1: Léxico
¿El output usa el vocabulario propio de la marca? ¿Aparece léxico prohibido? ¿Hay términos genéricos donde debería haber términos propios?
La revisión de léxico es la más rápida y la más objetiva. Puede hacerse en un pase de lectura de treinta segundos si el documento de voz tiene la lista bien construida. El revisor no necesita leer el texto entero: busca patrones concretos.
Criterio de paso: cero términos de la lista negra. Al menos tres términos del léxico propio en cada pieza de más de trescientas palabras.
Eje 2: Ritmo
¿Los párrafos tienen la longitud correcta? ¿La frase de cierre de cada bloque cumple con el patrón de la marca? ¿Hay frases de más de veinte palabras donde el estilo de la empresa exige frases cortas?
El ritmo es el eje más difícil de revisar y el más revelador. Un modelo puede aprender el léxico rápido. El ritmo tarda más iteraciones en calibrarse. Por eso es el eje que más feedback específico necesita en las primeras rondas.
Criterio de paso: ningún párrafo supera el límite de caracteres definido en el bloque 3. La frase de cierre de al menos el 80% de los bloques sigue el patrón documentado.
Eje 3: Ángulo
¿El texto ataca el problema desde el enfoque que la empresa usaría, o desde un enfoque genérico de sector? ¿La tesis del texto es reconocible como propia de la marca?
El ángulo es el eje estratégico. Un texto puede tener el léxico correcto y el ritmo adecuado, pero argumentar desde un lugar que no es el de la empresa. Esto ocurre cuando el documento de voz solo tiene atributos tonales y no tiene tesis ni posicionamiento documentados.
Criterio de paso: la tesis del texto puede rastrearse hasta una frase canónica del bloque de perfil tonal o hasta el posicionamiento documentado en el bloque de apertura/cierre.
La creación de contenido con IA que produce resultados estables parte siempre de este sistema de tres ejes, no de instrucciones de prompt aisladas.
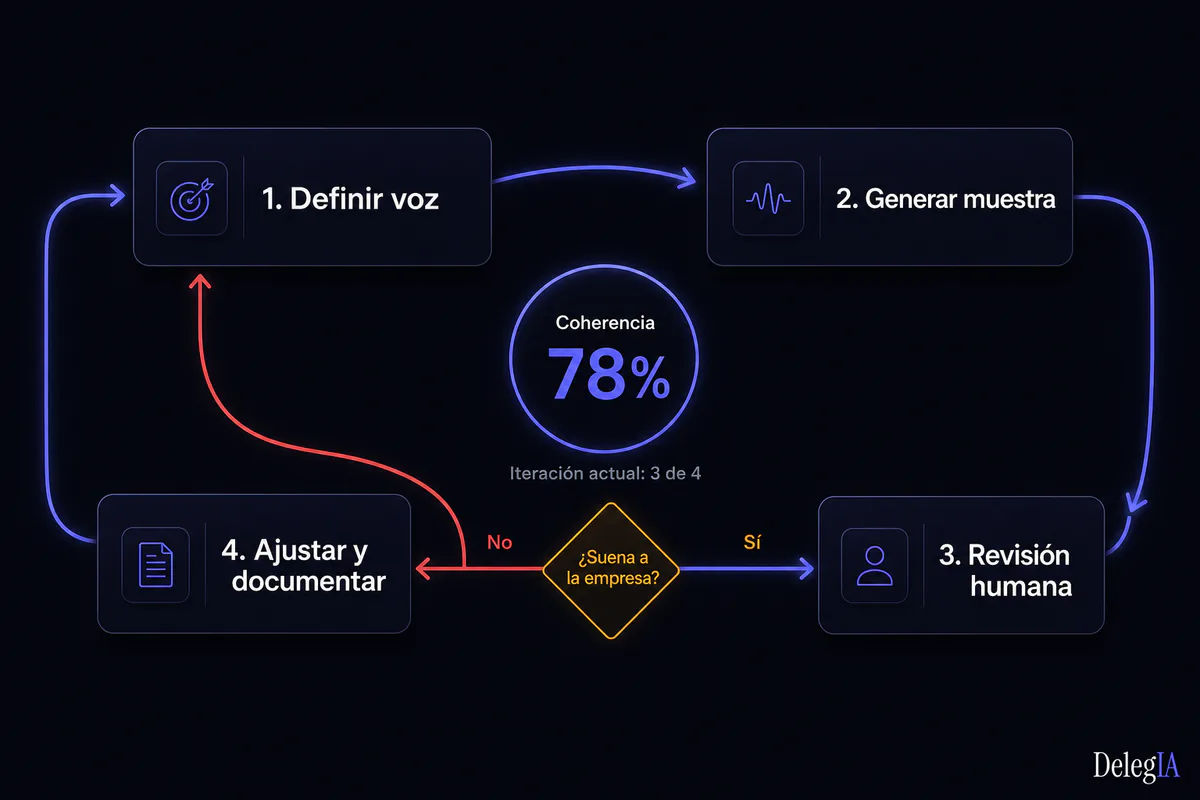
El workflow de entrenamiento: cuatro iteraciones con criterios de paso#
Instalar la voz en un sistema de IA no es un proceso de una sola pasada. Es un proceso iterativo con criterios de paso entre fases. Sin esos criterios, el equipo no sabe cuándo ha terminado el entrenamiento y cuándo está listo para producción.
Iteración 0: Línea base. Pedir al sistema un output sin ninguna instrucción de voz. Guardar el resultado. Este es el punto de partida documentado. Evaluar con la tabla de verificación del bloque 5 y registrar cuántos criterios falla.
Criterio de paso a iteración 1: haber registrado la línea base. No hay criterio de calidad aquí. Solo documentación del punto de partida.
Iteración 1: Léxico y antipatrones. Inyectar el documento de voz completo. Pedir el mismo output. Revisar solo el eje de léxico. Identificar los términos prohibidos que persisten y los términos propios que el modelo no usa.
Criterio de paso a iteración 2: cero términos de la lista negra en el output. Si persisten, ajustar la instrucción de léxico y repetir esta iteración. No avanzar con eje de ritmo hasta que el léxico esté estabilizado.
Iteración 2: Ritmo y estructura. Con el léxico estabilizado, revisar el eje de ritmo. Medir longitud de párrafos, longitud de frases de cierre, presencia de patrones de apertura. Documentar qué patrones no se transfieren con el documento de voz base.
Criterio de paso a iteración 3: el 80% de los bloques cumplen los criterios de ritmo del bloque 3. Si no se alcanza, añadir ejemplos de ritmo en el documento de voz (no más instrucciones abstractas: más ejemplos verificados).
Iteración 3: Ángulo y tesis. Con léxico y ritmo estabilizados, revisar el eje de ángulo. Comprobar si la tesis del output es reconocible como propia de la empresa o si es un ángulo genérico de sector.
Criterio de paso a producción: los tres ejes pasan en el mismo output. La tabla de verificación del bloque 5 tiene cero fallos. El sistema está listo para producción.
Si la iteración 3 falla en ángulo, el problema suele estar en el bloque 1 del documento de voz: el perfil tonal no tiene tesis ni posicionamiento. No hay más instrucciones que añadir al prompt. Hay que enriquecer el documento base.
Un sistema de voz calibrado en entrenamiento puede degradarse en producción. Ocurre cuando el contexto cambia: nuevo tipo de pieza, nuevo canal, nuevo tema fuera del ámbito de los ejemplos de entrenamiento.
La señal de degradación no es obvia. El output sigue siendo gramaticalmente correcto. El léxico sigue siendo mayoritariamente el correcto. Pero el ángulo deriva. La tesis se vuelve genérica. El ritmo se alarga.
El mecanismo de detección es la revisión periódica con la tabla de verificación del bloque 5, aplicada a una muestra aleatoria de outputs de producción. No hace falta revisar todo: con un 10% de la producción es suficiente para detectar deriva.
Cuando la revisión detecta deriva en el eje de ángulo, la respuesta no es ajustar el prompt. Es actualizar el bloque 4 del documento de voz con ejemplos del nuevo tipo de pieza o canal. El documento de voz es un artefacto vivo, no un documento cerrado.
El error más común al intentar mantener la voz con IA es intentar resolver los problemas de voz con ajustes de prompt. Añadir más instrucciones, ser más específico, prohibir más cosas en el mensaje al modelo.
Esto funciona hasta cierto punto. Pero tiene dos limitaciones estructurales.
Primera: las instrucciones de prompt no persisten entre sesiones en la mayoría de los workflows de producción. Cada vez que hay un cambio de contexto, las instrucciones se reescriben desde cero y la calibración se pierde.
Segunda: a partir de cierto nivel de complejidad, el prompt se vuelve contradictorio. Demasiadas instrucciones generan conflictos que el modelo resuelve de forma impredecible.
La solución es separar la capa de instrucciones de la capa de voz. El documento de voz operacionalizable es la capa de voz: estable, versionada, mantenida. El prompt es la capa de instrucciones: variable, específica de la tarea, sin responsabilidad de mantener la voz.
Cuando las dos capas están separadas, el sistema escala. Cuando están mezcladas, el sistema se rompe en cuanto cambia el contexto.
Preguntas frecuentes
¿Con qué frecuencia hay que actualizar el documento de voz?+
El documento de voz no se actualiza por calendario. Se actualiza cuando la revisión periódica detecta deriva en alguno de los tres ejes, o cuando la empresa incorpora un nuevo tipo de pieza o canal no cubierto por los ejemplos del documento base.
Una revisión cada trimestre es suficiente para detectar necesidades de actualización si el volumen de producción es de varias piezas por semana.
¿Cuántos ejemplos hay que incluir en el documento de voz para que el sistema funcione?+
Tres a cinco ejemplos verificados por bloque es el rango que funciona mejor en la práctica. Menos de tres no genera patrón suficiente. Más de cinco empieza a generar inconsistencias entre los propios ejemplos, especialmente en el bloque de apertura y cierre.
La clave no es el volumen de ejemplos: es que sean representativos y que no se contradigan entre sí.
¿El sistema de tres ejes funciona para cualquier tipo de contenido?+
Los tres ejes (léxico, ritmo, ángulo) son universales. Lo que cambia entre tipos de contenido es el umbral de cada criterio de paso. Un artículo largo tiene criterios de ritmo distintos a un caption de redes sociales. La tabla de verificación del bloque 5 debe tener una versión por tipo de pieza, no una única tabla genérica para toda la producción.
Conclusiones
Cómo construir un documento de voz operacionalizable, aplicar 3 ejes de revisión humana y entrenar el sistema para que el contenido suene a la empresa.
Si voz de marca IA ya aparece dentro de tu empresa, conviene revisar qué parte del flujo debe ejecutar la IA, qué datos necesita y quién valida el resultado antes de escalarlo.
El objetivo no es añadir otra herramienta, sino instalar una infraestructura que reduzca fricción, mantenga control humano y permita medir si el sistema mejora la operación.
El siguiente paso es aterrizar voz de marca IA en un caso concreto: qué proceso se quiere mejorar, qué datos lo sostienen y qué parte debe seguir bajo criterio humano.
Si necesitas ayuda para implementar IA en tu empresa con criterio, puedes solicitar un presupuesto y contarnos qué área quieres mejorar. Revisamos el caso y te respondemos en menos de 24 horas.
Implementa IA en tu empresa sin improvisar
Analizamos tu caso y te proponemos una infraestructura de IA adaptada al problema real, no un paquete genérico de herramientas.