
Tu academia, productora o consultora ya graba horas de contenido largo: webinars, masterclasses, podcasts, sesiones internas, formaciones para clientes B2B. Cada vez que se publica algo nuevo, alguien copia un fragmento al post de LinkedIn, otra persona corta un clip para Instagram y, dos meses después, nadie sabe dónde está el original ni qué piezas se sacaron de él. El reciclaje contenido largo empresa mediana IA tiene poco que ver con un GPT recortando subtítulos: es un sistema operativo donde el asset original vive en una capa central, los agentes especializados producen las piezas y un humano valida antes de publicar. Este artículo explica cómo se monta, paso a paso, en una empresa de 30 a 60 personas con un Director de Operaciones al mando.
El estado típico de una empresa que produce contenido largo sin sistema#
Una academia, una consultora o una productora B2B con 30 a 60 personas suele tener un patrón conocido. Hay una persona en marketing que graba clips a mano cuando se acuerda. Hay un freelance externo que monta carruseles cada dos semanas. Hay un Drive con 200 horas archivadas que solo se abre cuando alguien busca algo específico. La cadencia depende del calendario del Director de Operaciones, no del calendario de la audiencia.
El 94% de los profesionales de marketing dice que reutiliza contenido en algún formato. Lo que no aparece en esa cifra es la diferencia entre reutilizar con sistema y reutilizar a mano. La empresa que reutiliza a mano produce piezas con tres tipos de fallo: clips cortados con la primera frase aleatoria del podcast, posts donde se repite la misma idea cuatro veces en cuatro semanas, transcripciones publicadas tal cual que parecen un volcado de notas. La señal de contenido genérico no aparece en la pieza individual. Aparece en el patrón del feed.
A la vez, el 48% de los profesionales B2B identifica "no reciclar lo suficiente" como uno de los retos principales al escalar producción de contenido, según el B2B Content Marketing Benchmarks 2024 del Content Marketing Institute. La tensión es real: la empresa que no recicla deja valor en el archivo, y la empresa que recicla sin sistema satura el feed con piezas que se notan hechas con prisas. La salida no es producir más a mano. Es montar un sistema que opere sobre los assets ya grabados con criterio editorial codificado y agentes que respeten ese criterio. Producir más volumen sin esa estructura encaja con el patrón de automatizar sin arquitectura, no con el de escalar contenido. ## El asset original: qué grabar, qué etiquetar y qué descartar
El primer paso del sistema empieza antes de pulsar grabar. Un asset original sirve para reciclar si cumple tres condiciones: tiene una idea central clara, tiene bloques temáticos diferenciables y tiene claims con fuente cuando se citan cifras. Un webinar grabado sin guion, donde el ponente improvisa durante 60 minutos sin separar bloques, produce piezas pobres porque ningún agente sabe dónde corta una idea y empieza la siguiente.
La asset library es el repositorio central donde vive cada asset original junto con sus metadatos editoriales. No es un Drive con carpetas. Almacena, por cada pieza grabada, al menos siete campos:
- Identificador único, fecha y duración total.
- Tema principal en formato pilar de cluster, no descripción genérica.
- Invitado o ponente, rol y si aporta autoridad medible.
- Bloques temáticos detectados con minutaje de inicio y fin.
- Por cada bloque: idea central, claim con cifra si aparece y fuente del claim.
- Frases de marca utilizables tal cual, con minutaje de extracción.
- Anti-patterns detectados: ejemplos confidenciales de cliente, datos sin fuente, opiniones que no se sostienen sin contexto.
Estos metadatos se generan al ingestar el asset, no manualmente cada vez que se necesita una pieza. La transcripción se hace con un servicio especializado (Whisper, AssemblyAI, Rev), la segmentación por bloques con un agente que conoce el carácter de marca y la extracción de claims con verificación de fuente con otro agente con acceso a búsqueda. El responsable humano valida la asset library de un asset una sola vez, al ingestarlo.
Lo que se descarta también importa. Si un bloque temático contiene un dato sin fuente que el ponente recordaba mal, ese bloque queda marcado como "no reciclable hasta verificar fuente". Si un asset entero contiene material confidencial de un cliente concreto, queda marcado como "uso interno solamente". Construir bien la asset library evita reciclar piezas que pueden volver como problema legal o reputacional tres meses después.
La matriz de descomposición: del MP4 a piezas atomizables#
Una vez la asset library está poblada, la descomposición es el siguiente paso. La matriz de descomposición es un cruce entre dos dimensiones: bloques temáticos del asset por un lado, canales y formatos de salida por otro.

Una hora de podcast bien etiquetada suele contener entre cuatro y seis bloques temáticos. Por bloque, el sistema decide qué piezas salen y qué piezas no salen. No todos los bloques producen el mismo tipo de pieza. Un bloque con una historia narrativa funciona como clip vertical y como hilo de LinkedIn. Un bloque con datos y cifras funciona como carrusel y como sección de newsletter. Un bloque con una opinión polémica funciona como post breve y como cita destacada para email.
La matriz tiene cinco canales de salida estándar:
- Clip vertical (Instagram Reels, LinkedIn vertical, YouTube Shorts).
- Hilo de LinkedIn (4 a 7 posts encadenados o una secuencia semanal).
- Newsletter B2B (sección dentro de la edición de la semana).
- Carrusel visual con plantilla de marca.
- Artículo derivado de blog si el bloque aporta un ángulo no cubierto antes.
Según los casos que hemos instalado, la cadencia objetivo es entre 8 y 12 piezas por hora de asset original cuando la matriz está completa. Si una empresa graba 20 horas al mes, la cantidad teórica son entre 160 y 240 piezas. La cantidad real, después de gobernanza, suele estar entre 80 y 120 piezas publicables. En el patrón que hemos observado en empresas 7-8 cifras, esa caída del 50% no es un fallo del sistema. Es la gobernanza haciendo su trabajo.
Para entender cómo encaja la matriz dentro de la arquitectura completa de IA empresarial, conviene leer la arquitectura de IA empresarial por capas que sostiene este sistema.
Agentes y briefs: cómo se reparte un bloque temático en cinco canales#
Cada canal tiene su agente. Cada agente tiene su brief. Y cada agente trabaja contra el bloque temático y los metadatos asociados, no contra el MP4 ni la transcripción completa salvo que la pieza derivada lo justifique.
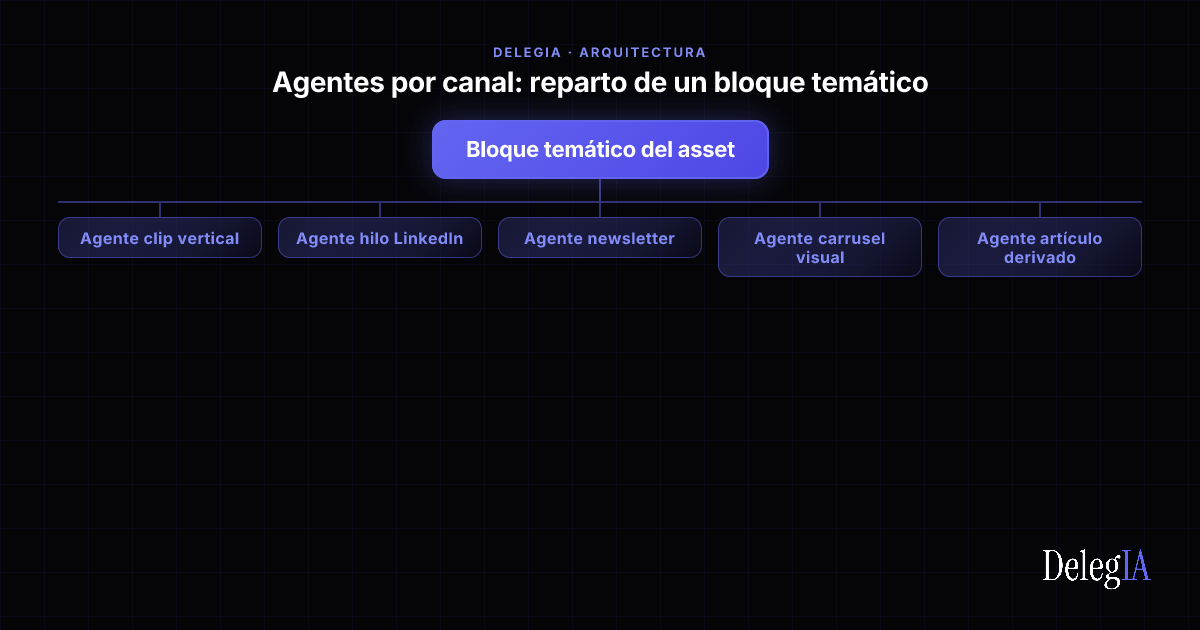
El reparto típico:
- Agente "clip vertical": produce 3 a 5 clips de 30 a 60 segundos por asset. Brief: gancho en los primeros 3 segundos, una idea por clip, sin texto en pantalla cuando el ponente habla, subtítulos generados desde la transcripción y verificados.
- Agente "hilo LinkedIn": produce 1 o 2 hilos de 4 a 7 posts cada uno. Brief: cada post se sostiene como pieza individual, no se publica el hilo completo el mismo día, voz de la marca consistente con el carácter editorial codificado.
- Agente "newsletter": produce una sección de newsletter por asset que entra en cola de envío. Brief: integrar el asset en el contexto de la edición, no ser el cuerpo entero del email, citar fuentes cuando aparezcan cifras.
- Agente "carrusel visual": produce 1 o 2 carruseles por asset. Brief: respeta la plantilla de marca, no inventa cifras, los claims llevan fuente al final, máximo siete páginas.
- Agente "artículo derivado": produce 1 artículo de 800 a 1200 palabras solo si el bloque aporta un ángulo no cubierto por otros artículos publicados. Brief: enlazar internamente, no canibalizar la keyword de un artículo previo.
La separación por agente y formato es lo que evita la trampa del GPT genérico. El 60% de los profesionales recicla cada pieza entre 2 y 5 veces, pero reciclar 5 veces sin agentes especializados produce 5 piezas casi idénticas. Reciclar 5 veces con agentes especializados produce 5 piezas distintas que cubren ángulos distintos del mismo bloque temático.
Si tu equipo lleva años produciendo contenido largo sin asset library ni agentes, el primer trabajo del sistema es construir la base operativa antes de tocar la producción de piezas derivadas.
Cuatro filtros editoriales antes de cada publicación#
La capa de gobernanza editorial no es un punto de control donde el responsable humano lee cada pieza línea a línea. Es un protocolo donde cada pieza pasa cuatro filtros antes de salir al público.
Filtro 1: claims con cifra. Si una pieza cita un porcentaje, una cifra o un benchmark, el filtro confirma que aparece la fuente y que el dato no se ha amplificado respecto al asset original. No se publica una pieza que diga "el 80% de las empresas" si el asset original decía "más de la mitad" sin fuente. Este filtro es automatizable si la asset library tiene el campo de claims bien poblado.
Filtro 2: tono y carácter de marca. Cada pieza pasa por una validación contra el bloque de carácter editorial codificado. Si la pieza usa lenguaje emocional, frases prohibidas o términos que la marca no permite, vuelve al agente con feedback concreto. Este filtro también es automatizable si el carácter está bien codificado.
Filtro 3: continuidad. ¿Esta pieza contradice algo publicado en las últimas seis semanas? ¿Repite una idea ya tratada con el mismo ángulo? Si el carrusel del jueves dice algo que el clip del lunes ya cubrió, una de las dos se reescribe o se aplaza. Este filtro requiere juicio editorial humano sobre lo ya publicado.
Filtro 4: saturación. ¿Cuántas piezas saldrán esta semana del mismo asset original? Si una empresa atomiza un webinar en 12 piezas y todas se publican en 10 días, la audiencia percibe spam aunque cada pieza sea técnicamente buena. La gobernanza distribuye las piezas en una cadencia razonable. Este filtro también requiere humano.
Solo el 39% de las organizaciones que usan IA reporta impacto medible en EBIT, y solo el 5,5% obtiene valor significativo del despliegue, según el State of AI 2025 de McKinsey. La diferencia entre los dos extremos casi nunca está en el modelo. Está en la gobernanza. Producir volumen sin filtros editoriales es lo que Google y LinkedIn empezaron a tratar como contenido genérico durante 2024 y 2025. La pieza individual no se penaliza. Se penaliza el patrón del feed.
Un Director de Operaciones bien equipado dedica 30 a 40 minutos al día a estos cuatro filtros, no horas. Y el sistema le presenta solo lo que requiere juicio humano, no la cola entera.
Caso: academia online de 35 personas implementando el sistema#
Una academia online de 35 personas con tres líneas de producto formativo (un programa intensivo, una membresía y formaciones de cliente B2B) graba al mes alrededor de 20 horas de contenido largo: cuatro masterclasses al programa intensivo, dos sesiones a la membresía y entre dos y cinco formaciones internas para clientes B2B según el calendario. El Director de Operaciones coordina marketing, ventas y producción con un equipo de tres personas en producción de contenido y dos en marketing.
Cuando este sistema entra a operar, la primera fase no es producir piezas. Es construir la asset library de las 200 horas de contenido grabado en los últimos doce meses. Esta fase tarda entre dos y cuatro semanas si los assets están bien etiquetados de origen, y entre cinco y ocho semanas si no lo están. Lo que el Director de Operaciones ve durante esta fase es archivado y metadatos, no contenido publicado.
A partir del mes dos, la producción de piezas derivadas entra en marcha. Con 20 horas mensuales de asset original, la cantidad publicable después de gobernanza suele estar entre 80 y 120 piezas al mes. La distribución típica: 40 a 60 clips verticales, 15 a 25 posts y hilos de LinkedIn, 4 newsletters, 6 a 10 carruseles, 1 a 2 artículos derivados. Esa cadencia es la base sobre la que se sostiene una distribución de contenido B2B operando con IA sin ampliar el equipo de producción, mientras la asset library se mantenga alimentada y los agentes reciban feedback de las piezas que peor funcionan.
A partir del mes tres, la asset library tiene cobertura suficiente para que el sistema detecte huecos: pilares de contenido sin cobertura, ángulos sobreexplotados, formatos sin asset original que justifique su existencia. El Director de Operaciones recibe un reporte semanal con esos huecos y decide si se graba un asset original específico para cubrirlos o si la cobertura actual ya es suficiente.
Este patrón es el que DelegIA instala como un sistema de departamento de contenido con IA en empresas medianas. La diferencia entre tener tres personas produciendo a mano y tener tres personas operando un sistema reciclable son tres meses de trabajo y un Director de Operaciones que pasa de coordinar producción a coordinar criterio.
La capa que más se rompe en empresas medianas es la de gobernanza editorial: hoy se delega en la persona con menos tiempo para juzgar criterio. Resolverla no es contratar a una agencia externa, ni añadir otro freelance al equipo de marketing, ni probar otro GPT que recorte clips. Es instalar la arquitectura por capas que opera la asset library con el criterio del fundador y libera al Director de Operaciones para coordinar criterio, no producción.
Cuándo el reciclaje deja de aportar y toca producir nuevo asset#
El sistema funciona mientras el asset original es relevante. Llega un momento en el que reciclar una pieza adicional aporta menos que producir un asset nuevo. Reconocer ese momento evita la trampa de seguir atomizando un asset que ya cubrió todo lo cubrible.
Tres señales que indican que el asset original está agotado:
Primero, el asset lleva más de dieciocho meses publicado y los datos citados ya no son los actuales. Una masterclass de 2024 que cita el 78% de empresas usando IA está desfasada cuando el dato actual es del 88%. Reciclar piezas de ese asset propaga el dato viejo a un canal donde ya no le corresponde. Mejor archivar el asset y producir uno nuevo con datos actualizados.
Segundo, el ángulo del asset ya no encaja con la oferta o el posicionamiento de la empresa. Si el podcast original hablaba de un servicio que dejó de existir, de un avatar que la empresa ya no atiende o de un partner que cambió de modelo, las piezas derivadas confunden al lector aunque sean buenas técnicamente.
Tercero, las métricas de las piezas derivadas caen sistemáticamente. Si las primeras tres piezas del asset funcionaron, la cuarta menos y la quinta nada, no es problema del agente. Es que el asset ya no tiene jugo y las piezas que aún se podían sacar ya se sacaron.
El sistema sano detecta estos tres patrones desde la capa de medición y avisa al Director de Operaciones antes de que se publiquen piezas que no funcionarán. Reciclar bien no es exprimir hasta el último clip. Es saber cuándo el asset ha terminado y cuándo toca grabar uno nuevo. Cuando un sistema con asset library, agentes especializados y gobernanza está en marcha, la decisión de grabar nuevo asset deja de depender del calendario del Director de Operaciones y empieza a depender de los huecos que el propio sistema detecta. Esa es la diferencia entre operar el reciclaje a mano y operar un sistema que opera el reciclaje por ti. Si tu academia, productora o consultora ya graba horas que se quedan en archivo, el siguiente paso no es contratar a otra persona ni comprar otra herramienta de edición. Montamos la arquitectura que descompone, gobierna y publica con criterio editorial codificado, instalada dentro de la empresa, operando con tu criterio. ## Lo que dejamos funcionando: el sistema de reciclaje, no una herramienta
El reciclaje de contenido largo funciona porque hay un sistema operando dentro de la empresa: la matriz de descomposición codificada con el criterio editorial, los agentes por canal entrenados con el material existente y los filtros editoriales que validan antes de cada publicación.
Cuando dejamos esto instalado, lo que la empresa tiene no es una herramienta nueva, es una capa que opera el ciclo completo: del MP4 a las cinco piezas, de las piezas al calendario, del calendario a la publicación con la voz del fundador. Marketing pasa de coordinar el reciclaje a aprobarlo. El asset original deja de morirse en la primera semana y empieza a generar tráfico durante meses, sin sumar personas al equipo.